From Bitswap to CAR Pool pt 1
Introduction
This is an exploratory, informal set of notes+questions+references+& possible opines through my journey learning about Bitswap, and why some are breaking up with Bitswap, and then venturing into CAR Mirror for point-to-point (unicast) data transfer, and finally into thinking what CAR Pool may look like for one-to-many and, even, many-to-many data transfer and communication. I’m probably, consistently wrong throughout this, and some of this will probably be redundant for those well into the space.
With the Move The Bytes Working Group in existence and measurement becoming a major vocal point in the IPFS community, it seems like we’re finally giving context exchange an extended look:
We argue that content exchange itself at the protocol layer has not been looked at to the extent it deserves.
Content Discovery AND vs OR Data Transfer?
Today, Bitswap is used for both opportunistic content discovery/routing and data transfer, where in the former case, communication falls back to the DHT if no swarm peer replies to a WANT message. Pinning services like Pinata place more reliance on Bitswap for “faster” content discovery, wanting to rely less on the DHT. Let’s look at how the Sigcomm IPFS paper breaks down IPFS publication and retrieval:
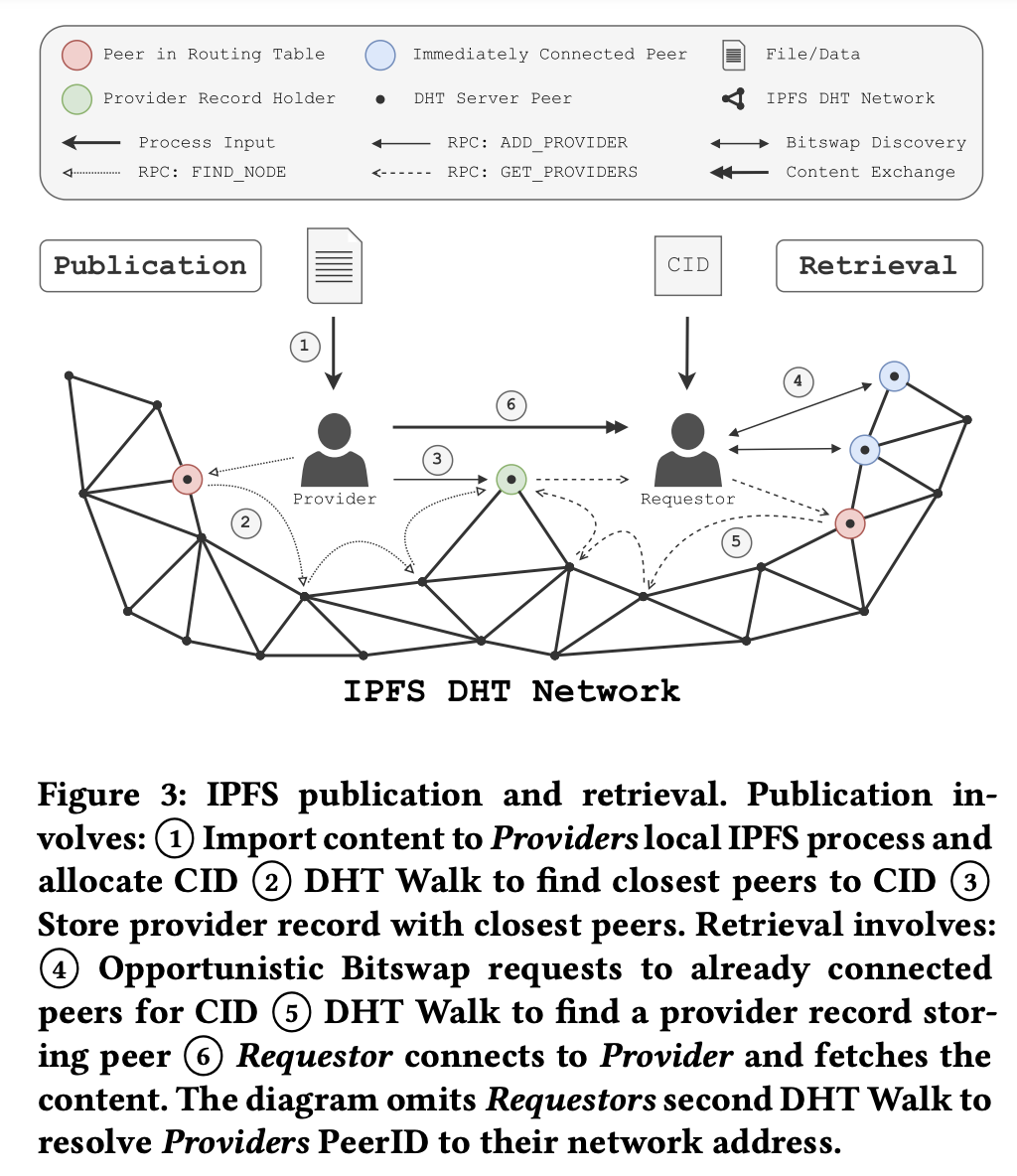
Bitswap is used in both (4) (Content Discovery) and (6) (Content Exchange, after peers are identified). Why can’t we leverage just the DHT for Content Routing and Discovery?
Accelerating Content Routing with Bitswap: A multi-path file transfer protocol in IPFS and Filecoin shows why:
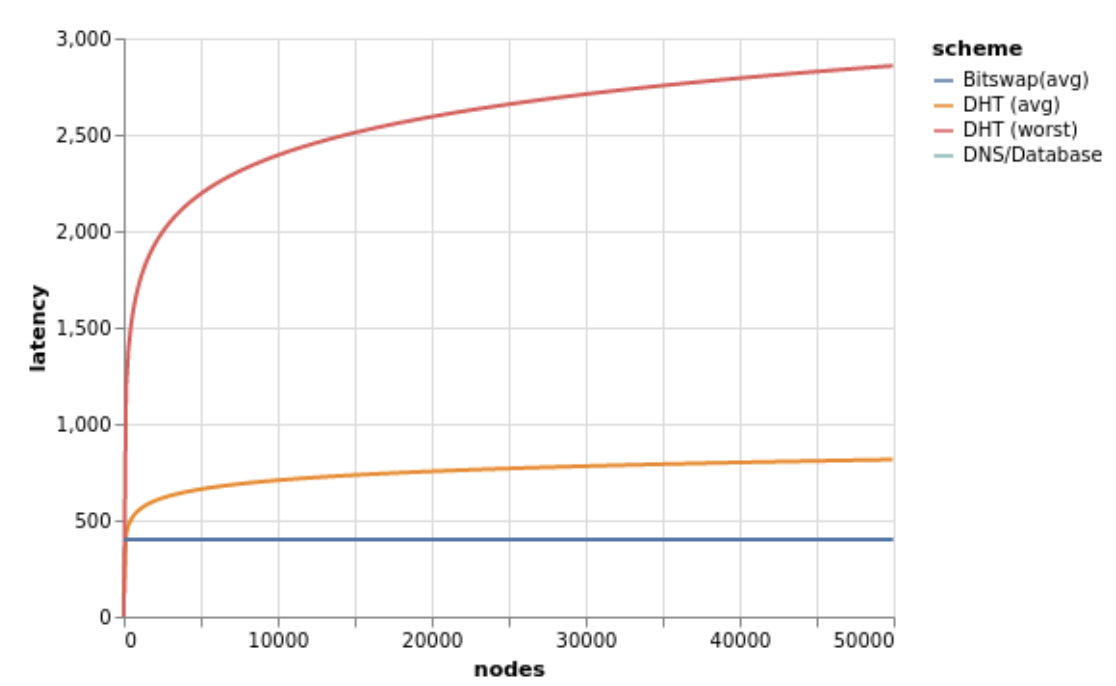
DHT lookup and fetching are slow. “Bitswap is able to discover and retrieve a block in at most 2 RTTs”. With the Kademlia DHT (which IPFS implements), the worst case is:
time_to_fetch_DHT = (1 + log2 N/R) ∗ RTT where i is the size of the network in terms of the number of N nodes; R is the popularity of the content.
As the network grows, DHT fetching latency gets worse and the overlay structure does not necessarily represent the network topology, i.e. one hop in the DHT can be many network-layer hops and reroutes. Maybe we’re putting too much on Bitswap to be both a means for content routing and data transfer due to suboptimality with the singular DHT used today.
This post is not necessarily about DHT optimizations and historical design per se, but I highly recommend David Dias’s survey and discussion on DHT research and how leveraging a multi-layer DHT and/or named-based routing and forwarding, akin to work espoused by the NDN group, could be the solution. Personally, as someone who’s researched and applied ideas from modern networking research, there’s so much more to leverage from lower-level networking protocols and packet-layer optimizations. I’ll come back to this in another post.
Of note, the “newish” Hydra DHT server was designed to optimize content routing to distribute provider records across more peers and proactively search for provider records if not directly fed “into the Hydra”. Nonetheless, Trautwein’s recent presentation on the implementation showcased no significant, clear wins around DHT lookup latency:
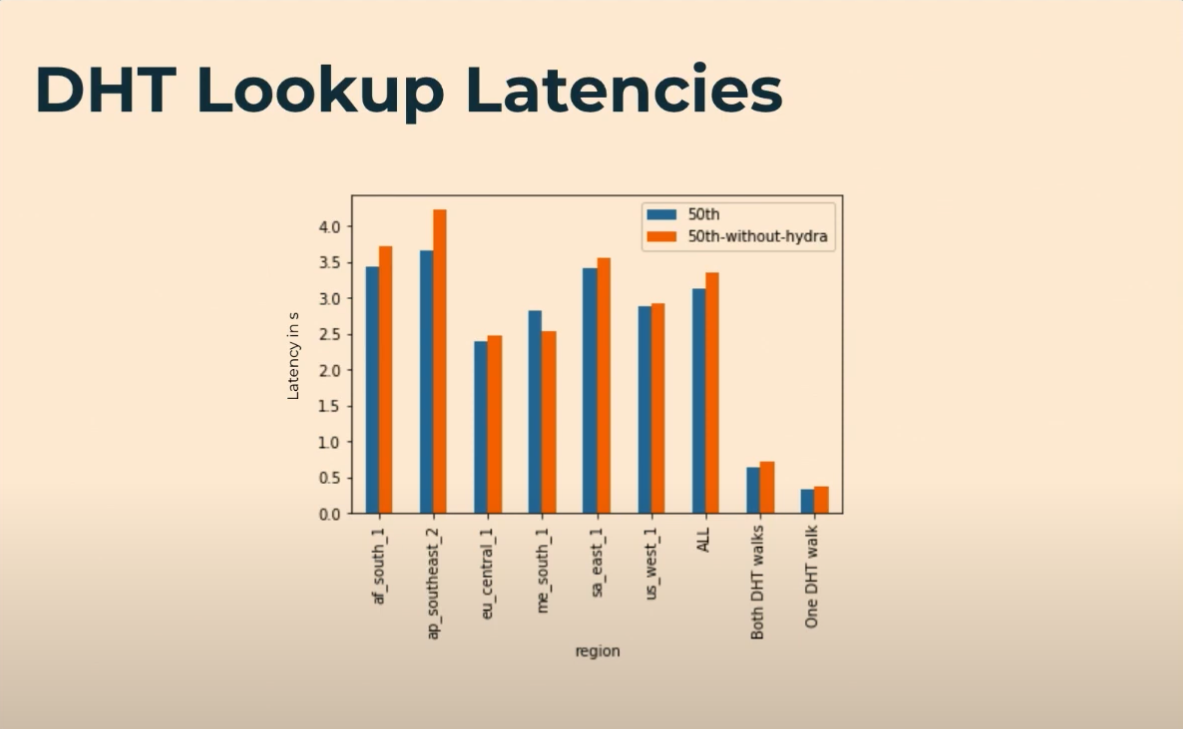
Trautwein even states:
From this study, we could conclude that the Hydra’s don’t actually really speed up the DHT Lookup process, as is intended.
Regarding DHT optimizations, this is unsettling.
Also in the domain of content discovery improvement has been the launch of network indexers (akin to supernode indexers), which have been deployed to enable search for data available from known storage providers running on Filecoin and IPFS networks. An indexer node ingests advertisement messages announced by storage providers over a gossip pubsub or HTTP. While this approach may be more suitable for Filecoin generally, upon measurement, it too should lack significant impact on DHT Lookup performance (going off the Hydra work results).
Should we “break up” Content Discovery from Data Transfer?
(from dig’s talk ~ https://www.youtube.com/watch?v=ZSKIVPv0rDQ&list=WL&index=4)
The reason we’re not enamored with Bitswap is also due to performance:

@expede’s excellent CAR Mirror / CAR Pool presentation, the Move the Bytes notes, and the beyond Bitswap project, among others, identify multiple issues with Bitswap, including:
- A one-sized fits all implementation that doesn’t match every need/case;
- Doesn’t account for the IPLD structure of the data whatsoever;
- That it’s not good w/ nested, deeply, cross-linked data (like filesystems) with depth-heavy trees vs breadth-heavy ones (a Fission case in particular);
- Bandwidth inefficiency, as it sends too many messages. Many solutions in the post-Bitswap world aim to reduce redundant bandwidth and communication rounds by narrowing the sync space while minimizing block deduplication.
- Of note, Bitswap is very focused on fully limiting block deduplication in its transfer approach; however, some solutions may not care about deduplication at all.
If we choose to split up data transfer from discovery, are there possibilities to enhance the performance of DHT operations, and concentrate on removing Bitswap with a better transfer protocol? Or, do we keep Bitswap for content discovery only and go with other options for just data chunk exchange?
In Hannah Howard’s Future of Decentralized Data Transfer presentation on Graphsync and Bitswap, the goal seems to be more than just transport, with a better future toward optimizing for supporting custom solutions:

However, in the measurement section of Trautwein’s Hydra talk, this graph on CID provider distribution is shown:
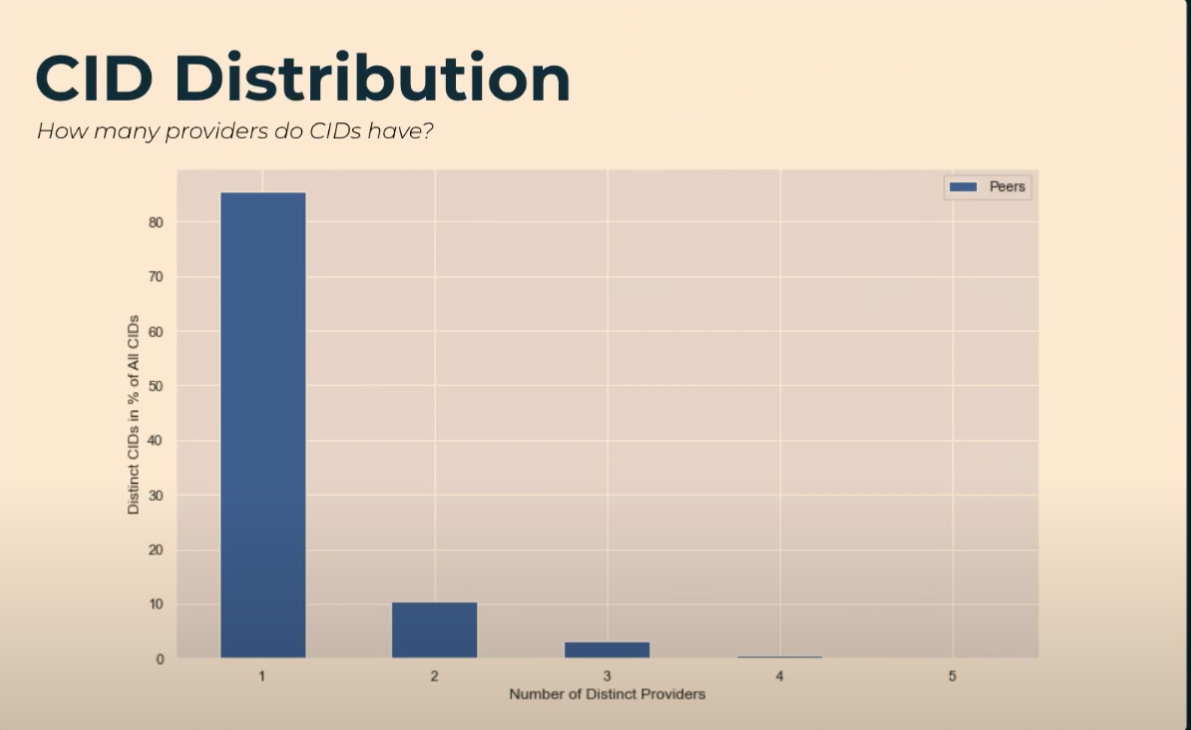
If most CIDs only have a single provider, does content discovery matter as much in terms of trying to solve both content exchange and discovery? The yinz at n0 want the focus to be on data transfer. Additionally, our work on CAR Mirror, which leverages the CAR format that can be expressed as a streaming data structure, is explicit about not being a discovery protocol; instead, focusing on efficiency and reducing the number of round trips in a session. One of its assumptions is that the provider has at least some of the (necessary) data, which seems to mirror CID distribution generally.
So, as a community, the go-to direction seems to be headed toward a separation, which the working group has demonstrated thus far.
If you have to transfer data, transfer only that which is necessary.
For posterity, let’s dive into Bitswap a bit more closely
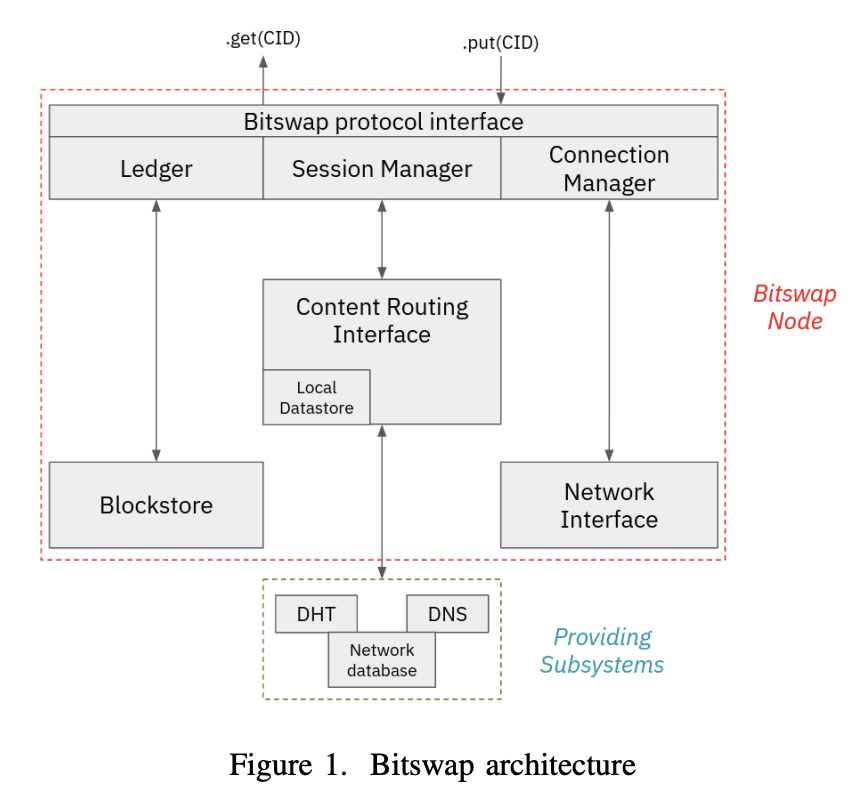
The above image documents the architecture of a Bitswap node. The main set of operations in an exchange consist of
- Initiating a request session with a WANT-HAVE wantlist message with the root CID. This will typically take advantage of the Connection Manager which really only comes in handy if discovery worked in the first place.;
- Traversing the DAG by constructing a new WANT-HAVE request with 2nd-level CIDs to nodes within the session. Transfer happens over WANT-BLOCK requests and the process is an iteration over WANT-HAVE messages for block retrieval and WANT-BLOCK for block transfer until the full Merkle DAG is traversed;
- Peer Selection for probabilistically choosing peers to exchange data with, based on tracking successfully sent blocks over time; and
- Triggering lookup operations in the content routing subsystem when falling back to the DHT is needed when connected peers respond with DONT-HAVE messages.
This series of operations demonstrate the discovery/transfer combo in action, which adds a lot of ceremony beyond content exchange.
Improvements Left on the Cutting-Room Floor
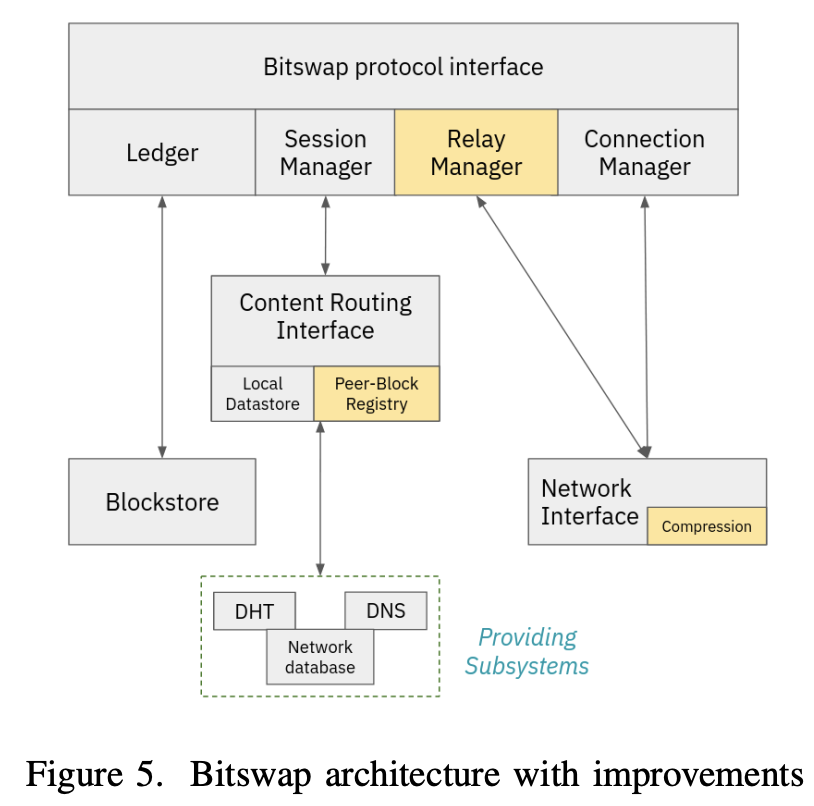
The beyond Bitswap research engineers interestingly modeled, measured, and implemented a set of extensions for optimization, more concerned with content discovery, however. These included:
- Adding a TTL field to Bitswap messages, driving content routing as TTL-formed trees, extending the range of discovery, using controlled message flooding, and avoiding lookup on the DHT. More of this is covered in Teaching Bitswap Nodes to Jump | Protocol Labs Research, including newfound issues with message duplication.
- The addition of a relay manager/component for tracking WANT messages and CIDs being requested on behalf of other nodes. When a node receives a block from a request belonging to some other peer, the relay manager forwards the block to the source, following the same path as the original request (symmetric routing). The relay manager is also used to limit the
outreach of requests and avoid flooding the network. We’ll come back to the relay component later. - WANT message inspection so that the content manager can inspect messages and store the information in a peer registry, mapping a CID seen by the node to the peers that have recently requested this particular CID. Essentially, this means checking if peers already requested the content before content exchange.
- Stream Compression, which uses a stream wrapper to compress every byte that enters the stream writer of a node at the transport level. For CAR Mirror, this also hints at why transmitting CAR files as a streaming data constructor is a good idea/bet.
A note about Measurements
The key for every new transfer protocol or extension is measurement. I won’t cover this much, as it’s been a major part of n0’s recent efforts, and we’re looking to tap into using testground for CAR Mirror performance benchmarking and simulation as well. But, yeah, measurement is key, and testground can simulate between 2 and 10k nodes while also scheduling groups to be run via a Docker-compose-like setup or as a k8s cluster that can run on AWS.
Speaking from what I know about CAR Mirror and kubo plugin implementation, the focus is data transfer and we’re moving toward the stage to iterate while measuring tail latencies. I’ll let @justinjohnson @jonathan.essex jump more on that, however.
Moving to CAR-Pooling?
CAR Pool is meant for many-to-one and even many-to-many data transfer, where we can then
- recover multiple providers
- stream data in parallel across multiple parties
- provide a means for work sharing
- and a stepping-stone toward ad-hoc trustless network seeding and bootstrapping
This post won’t cover the future around ad-hoc seeding and bootstrapping, though it’s definitely the longer-term goal, and IPFS doesn’t yet provide a seamless swarm model for bootstrapping; though there always are interesting ideas. For now, we’ll have to assume trusted clusters, e.g. the Fission cluster, PL’s one, or one of the trusted storage providers, etc.
While unicast, one-to-one, data transfer (particularly w/ nested trees) has a path forward with CAR Mirror, the group setting is somewhat different. How so?
- Firstly, communication now has to take place across n number of peers within a multi-party provider cluster, or sub-cluster (if dealing with larger group/fleet deploys), in the background. These nodes all have to reconcile and “share” the same view of content data in order to provide content to “clients” outside the designated group/fleet.
- For multi-provider sharing, transport should always take advantage of parallelism.
- Within a designated grouping, the transfer of blocks among nodes needs to have minimal communication overhead across the reconciliation graph. For example, if we have a cluster containing nodes A, B, and C, where A and B are in one region, and C in another, to sync blocks, both A and B shouldn’t have to sync with C. A more optimized scenario would be A syncing with B, and B syncing with C separately, so that at least one leg of transmission has a lower cost. This essentially means we have a preference list for selected senders, and that peers have to know what the cost or weight is for peers in its group graph. Determining the most optimal routing is akin to how routers and switches work in networking via a spanning tree.
- As with CAR Mirror, we even want to narrow the sync space and leverage linear sketch data structures for group reconciliation. We know that a designated group/set must share the same data; there is always overlap.
- Client nodes (e.g. iPhone in @expede’s talk) need to relay what content they need by communicating to a coordinator node within the trusted group, and that coordinator can determine how and who among the group can best fulfill the request for that client. This is why it’s a many-to-* relationship.
For now, let’s focus on how a trusted group of provider nodes could/should share information within their designated set (in the background).
Sketches are Dope?
I’ve heard rumors that even bloom filters are considered too complicated :). In group reconciliation and replication (at some scale), efficient exchange of graph data doesn’t come complexity-free. Having worked extensively with Riak Search (syncing two systems, Solr and Riak KV) and Riak’s Active Anti-Entropy sub-system back in the day, group reconciliation needs a good, thorough design. Data structures become more important, especially if we’re choosing eventual consistency (as we should in this case).
@expede has already made the case for Bloom filters in CAR Mirror’s source-to-sink approach:
It would be impractical (and indeed privacy-violating) for the provider to maintain a list of all CIDs held by the requestor. Sending a well-tuned Bloom filter is size efficient, has a very fast membership check, and doesn’t require announcing every block that it has.
In the clustered, multi-party setting, for sketches, we’re aiming for space complexity, mergability without loss of information, and completeness, where both the
content information (such as a fingerprint representing element identity) and the affiliation information (the sets an element belongs to) are correctly represented. This last property is very important and is a major motivation in MCFSyn, which we’ll get to in more detail shortly.
Sketchy, Sketchy Data Structures
Whereas bloom filters work well in a two-party setting like CAR Mirror and are space-efficient (optimized for memory usage, not access), in the clustered scenario, many of its variants either lack mergability or assume that an arbitrary element x exclusively belongs to a set, which doesn’t fit here. It’s just not made for general multisets, which allow elements to appear multiple times.
Much of CAR Pool discussions thus far, including some deeper dives by @matheus23, has looked to Invertible Bloom Filters (IBFs) as the means for efficient multiset synchronization. Of note, Invertible Bloom Lookup Tables (IBLTs) come into play much more in the literature, as an extension to the original IBF work. The IBLT is also space-efficient and most definitely mergeable; however, it also fails to achieve the completeness property mentioned above and can seldom judge and decode the affiliation of the different elements correctly, particularly in larger difference sets. So, for this post and upcoming spec, I propose we should try something else.
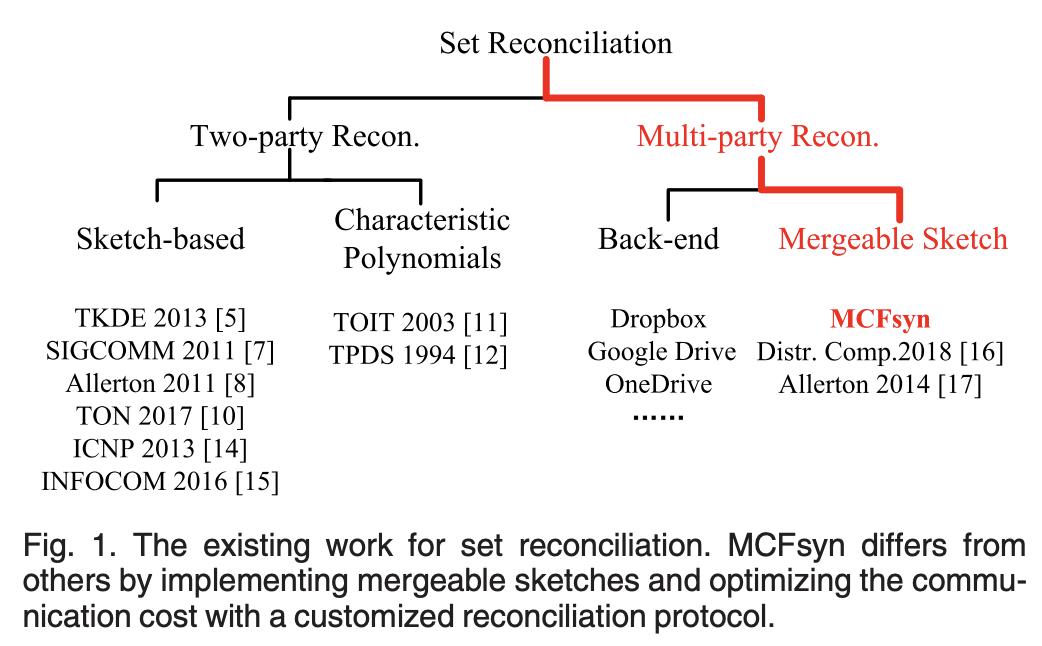
There are a ton of set reconciliation schemes, methods, and protocols, including Parity Bitmap Sketch (an Error-Correction Code-based scheme), Graphene (leveraging BFs and IBLTs for blockchain propagation), Cuckoo Filters, and more. Frankly, it’s overwhelming and daunting literature! However, a key through line amongst the work is that much of it is either 2-party (A ↔ B) oriented or doesn’t achieve its stated properties and/or performance bounds when lifted into the multi-party setting.
From the MCFSyn paper:
As for multi-party set reconciliation, it is usually decomposed as multiple rounds of two-party set reconciliation… We note that most recently, the IBLT and characteristic polynomial are generalized from two-party set reconciliation to multi-party scenarios.
Here’s a view into the existing research and where it falls into:
Proposal: Something like MCFSyn—with modifications
In my findings, the MCFSyn paper seemed to be a really great fit, particularly because it calls out this completeness property and is very explicitly about multi-party reconciliation, detailing a framework for how sync should happen among a group of peers in a set. It also presents a solid evaluation against the IBLT, though still lacking a real-world, major-scale evaluation (a problem throughout the set reconciliation literature, sadly).
MCFSyn presents a new variant of the cuckoo filter named the marked cuckoo
filter (MCF), to represent the sets in each reconciliation participant. The MCF attaches an additional field, called the mark field, in each slot to describe which set(s) the stored fingerprint belongs to (earlier to the reconciliation).
Firstly, what’s a cuckoo filter:

As you can see, cuckoo filters provide bounded false positive probability and the ability for deletion (important for a cluster that may share tombstones). Of note, cuckoo filters generally work well for asymmetrical compute (as in circumstances like multi-party reconciliation) and set sizes starting around 10^4 or 10k elements (coming from the GenSync benchmarking paper, directly linked below)
Secondly, how does the MCF work:
For example, given three sets S_1, S_2, and S_3, it has three bits in each MCF slot (in addition to the fingerprint) to indicate the affiliation of the stored element. The ith bit will be set to 1 if S_i contains that element. MCF naturally inherits the functionalities from the standard cuckoo filter, including element insertion, query, and deletion. Additionally, MCF enables filter-level operations, such as aggregation and subtraction, so that the MCFs from different sets can be aggregated together or subtracted pair-wisely. Such a design allows MCF to be space-efficient, mergeable, and complete.
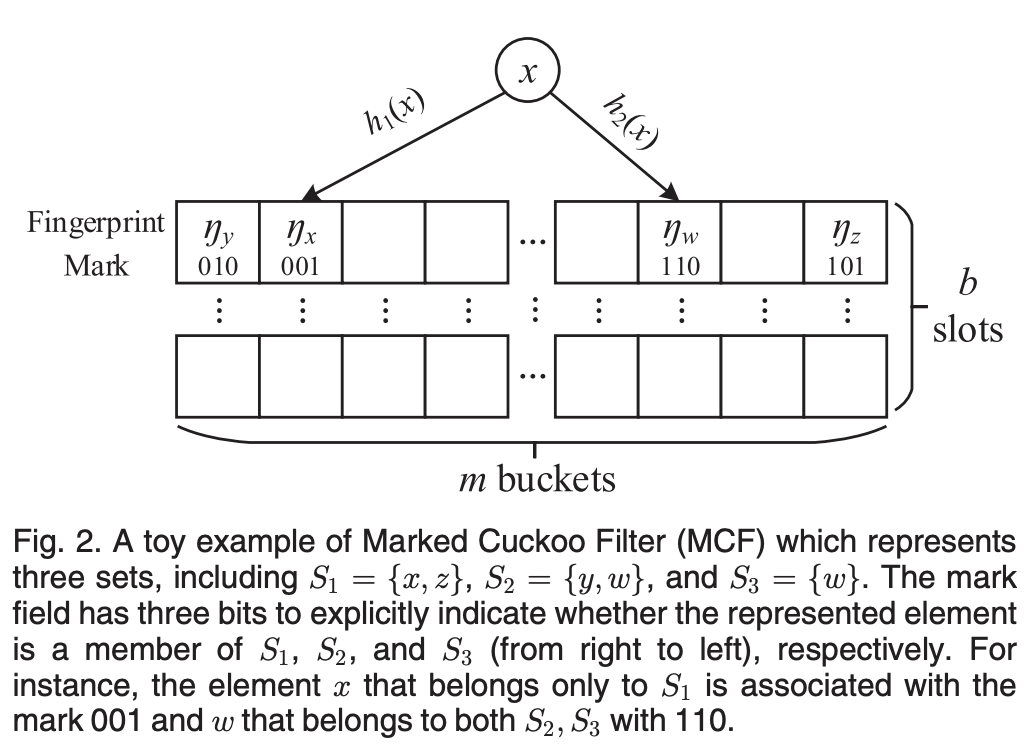
Intrinsically, the MCF represents affiliation information (the sets an element belongs to) for each node and its representation jointly considers the fingerprint and marked-field slots.
The Reconciliation Protocol at a Glance
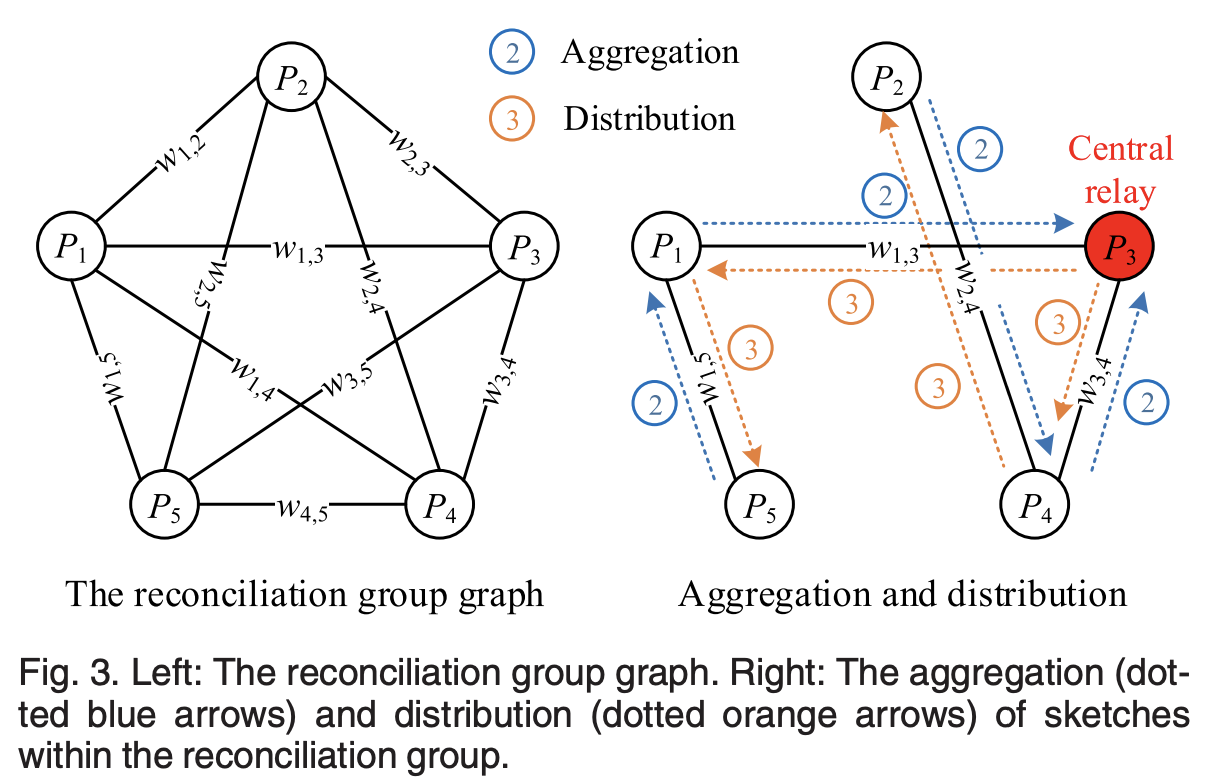
There are 5 major steps in the protocol:
- Forming the Representation of local elements, which is the MCF itself.
- Aggregation of sketches to all participants in the group, which are sent to a logically chosen central relay in parallel (more on this soon). These sketches are aggregated together to produce a global union sketch: S_{union} = \cup_i \ S_i. This relay must be a participant within the group itself.
- The logical relay then distributes the aggregation results to all participants in parallel.
- Once received, each participant traverses the unioned, global sketch to determine both missing elements (those not from the local set) and exclusive elements (those that belong to the local set).
- Data transfer/Transmission occurs as different elements in \cup_i \ S_i - \cap_i \ S_i are transmitted to selected senders to accomplish the reconciliation task.
As you can see in the figure showing both aggregation (2) and distribution (3), aggregation happens in parallel, exploiting a minimum spanning tree (MST) in their framework, and internal participants can even aggregate sketches from children in its graph before sending it along to the central relay. After aggregation at the central relay, the relay distributes the unioned MCF to all the others over the MST.
Extraction is probably the most complicated part of the protocol, as it determines missing and exclusive elements separately, per this algorithm:

Once extraction is executed, for transmission, a participant P_i will push its exclusive elements in D_{E_i} to other participants by either broadcasting directly to save time or spreading along with the MST to achieve optimal communication cost. For a missing element in D_{M_i}, if its corresponding mark field only has one non-0 bit then this element is an exclusive element of another participant’s sketch. Therefore participant P_i will do nothing but wait until receiving that element content from that element provider, as it will be transmitted by them. By contrast, if there are multiple 1’s in that mark field, participant P_i selects the participant with which it establishes a link with the lowest weight as its provider. This strategy is implemented as a preference list based on the reconciliation group graph. In this list, a neighbor with a lower-weight link gets a higher preference,
Of note, both the central relay and the weighting between edges in the spanning tree can be driven by different heuristics.
Dynamic Reconciliation ~ Heterogeneity vs Homogeneity
For the core protocol, the paper mainly explores Homogeneous MCFs or those with identical
parameter settings, including filter length m, hash functions for fingerprints and candidate buckets, and the number of slots in each bucket b. In a homogeneous cluster, things have typically been on the good path and the set difference is generally more minimal per run and traversal. However, most dynamic systems, have nodes in a group that holds many fewer elements than others. Nodes go offline or could experience a coma (really offline!), or there could be a sudden flurry of content updates, e.g. the Red Wedding Problem. For these dynamic reconciliation cases, time-complexity can increase from O(mb) to O(m_i \ b_i + m_j \ b_j) and the data structure is re-designed so that the candidate buckets are derived out by the fingerprint, changing how the aggregation algorithm works. I’ll leave more to the paper for this point.
The other interesting reckoning that heterogeneity brings to MCFs is that normal MSTs may not be as optimal or economical, as there is a trade-off between the communication cost and the computation complexity. Therefore, there’s lots of room to determine better how best to handle routing in such situations. Another way to save on bandwidth over the wire is to choose the central relay that has the most content, and this seems to hint that a central relay could also be specified indexer-like nodes.
Evaluation(s)
As with many of these set reconciliation papers, the evaluation, while thorough, lacks that real-world, Google-scale Sigcomm evaluation. Nonetheless, for communication cost, comparisons to IBLT simulations look uber-promising, even across diverse strategies:
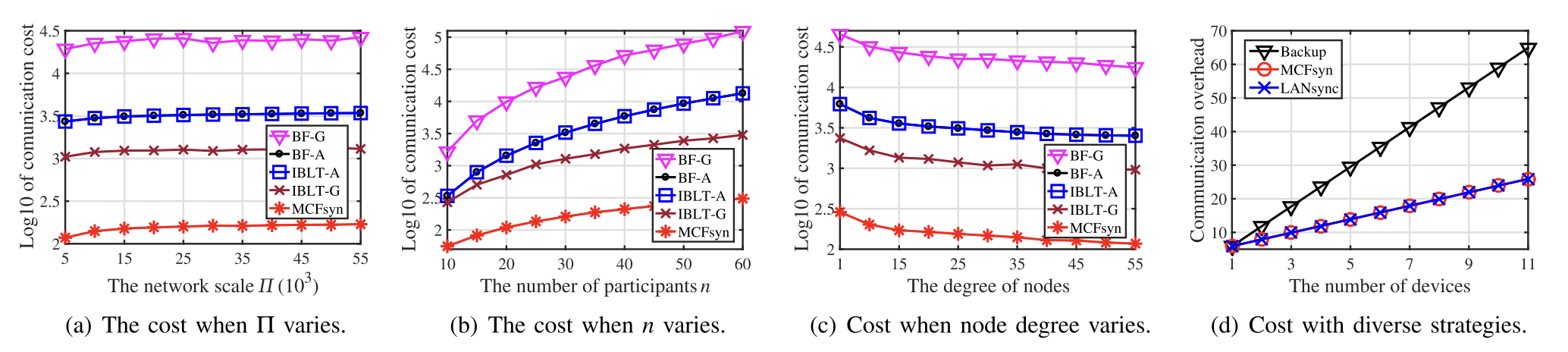
To add to the completeness properties mentioned earlier, the paper evaluates how IBLTs correctly decode difference sets in varying scenarios:

Discussion: CAR Pool + Mods: High, High-Level Notes
So, what does a variant of MCFSyn look like for trusted cluster providers protocol like CAR Pool? In no order:
- The algorithm(s) and data structure themselves are very “implementable”, or just a bit of coding :), but the marked cuckoo filter with aggregate element information seems like a key approach. Mainly, the goal of completeness seems super necessary.
- The edge cases need to be enumerated, as clustered replication is still the gift that keeps on giving.
- CAR Mirror**-like** data transfer can still be used at the transmission stage (without the blooms of course—just pure transfer), post aggregation/dissemination.
- Aggregation and transmission between nodes in the graph should leverage something akin to the TTL-formed tree (instead of MST) that the beyond Bitswap group has discussed and measured. So, we also propose TTL on messages within this MFCSyn-like reconciliation system, and this should be known directly by each node or queryable via the relay node.
- The cluster (or sub-clusters in a fleet model) should choose two central relays at any active point, a primary and a secondary, possibly determined by rendezvous hashing on node IDs for the cluster. If a primary goes offline, the secondary moves into the primary role and a new secondary is chosen.
Otherwise, if a secondary fails, a new secondary is ready to go.- These relays would also act as coordinator nodes within a peer group.
- The choice of the central relay(s) should use a heuristic like most content stored, or most popular content aggregated.
- Associated with one of @expede’s comments in the CAR Mirror/Pool video, the most popular content should be shared in the background by trusted clusters.
For Another Post
- In another post, as we get closer to a spec, we’ll cover provider coordination for fulfilling content requests to the client(s).
References
- How Bitswap works
- Invertible Bloom Filters talk by @matheus23
- CAR Mirror Spec
- CAR Pool and more
- Measuring the Web3.0 Stack
- Move the Bytes WG Kickoff
- Move the Bytes Mtg 1
- Open Problems: Enhanced Bitswap/GraphSync with more Network Smarts
- Beyond Bitswap
- The IPFS Network From The Hydra’s PoV
- Introducing the Network Indexer
- Future of Decentralized Data Transfer
- Routing at Scale
Papers
- Accelerating Content Routing with Bitswap: A multi-path file transfer protocol in IPFS and Filecoin
- MCFsyn: A Multi-Party Set Reconciliation Protocol With the Marked Cuckoo Filter
- Design and Evaluation of IPFS: A Storage Layer for the Decentralized Web (Sigcomm)
- Space- and Computationally-Efficient Set Reconciliation via Parity Bitmap Sketch (PBS)
- Adaptive Edge Content Delivery Networks for Web-Scale File Systems
- The Hash History Approach for Reconciling Mutual Inconsistency
- Cuckoo Filter: Practically Better Than Bloom
- GenSync_A_New_Framework_for_Benchmarking_and_Optimizing_Reconciliation_of_Data.pdf (9.7 MB)
- Invertible Bloom Lookup Tables