Background
Imagine that an agent comes online, and learns that the latest remote revision of a public WNFS tree is different from the local revision. This means one of three things:
- The local tree is an ancestor of the remote tree (i.e. the remote is strictly newer)
- Fast forward the local tree to point at the remote revision
- The remote tree is an ancestor of the local tree (i.e. the remote is strictly older)
- Nothing needs to be done to the local tree
- Both trees have diverged (but share a common ancestor)
- Run the reconciliation algorithm (i.e. choose the revision with the lowest hash)
In order to determine which case we’re looking at, the lowest common ancestor of both trees must be found. This is a process that can take some time, and may be worth optimizing.
Current Approach
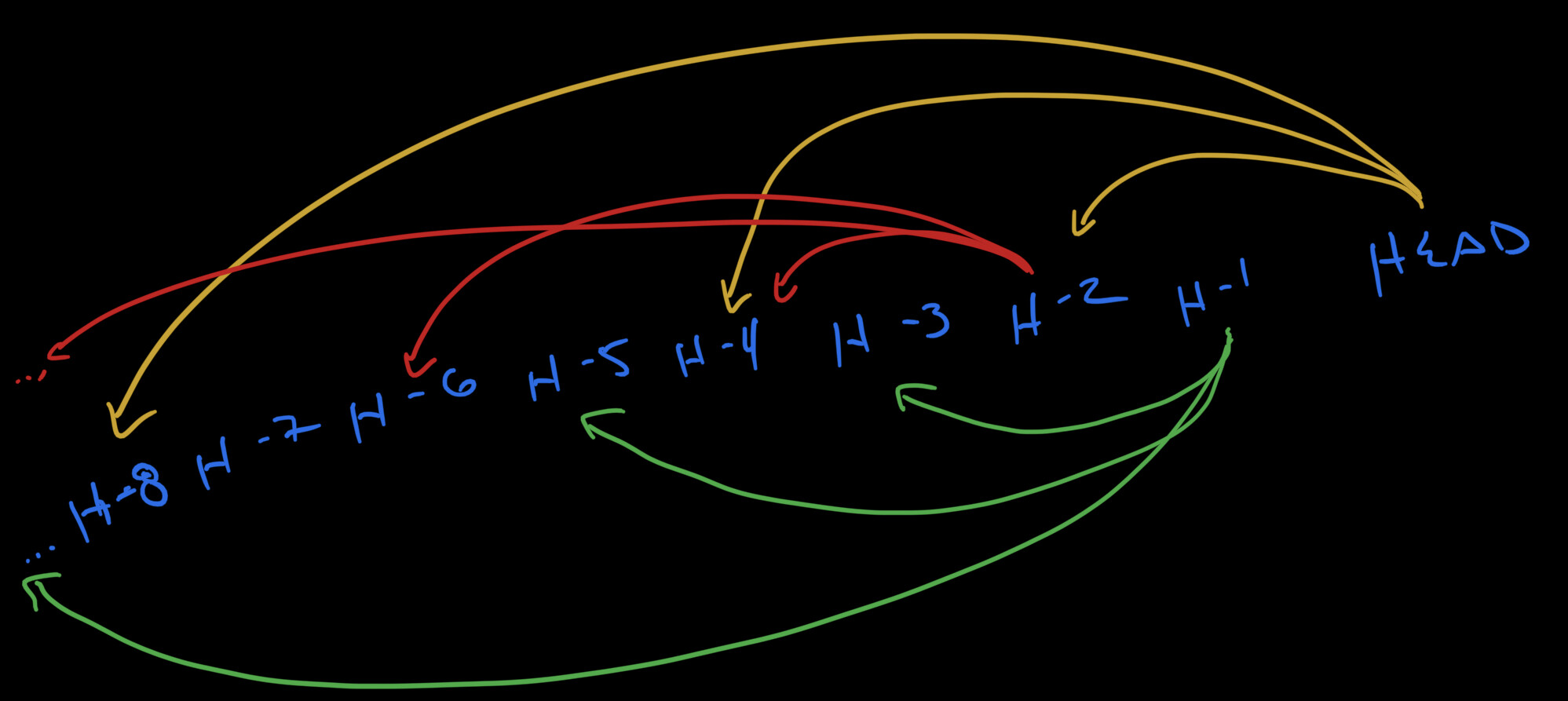
As I understand it, the current approach is to walk backwards through the history for both trees, until you find a common node. Since this traversal happens one revision at a time, if two trees have diverged over many updates, it may require many round trips in order to locate this ancestor.
Proposed Alternatives
1. Skip List
I’m not super familiar with the specifics of this proposal, and I believe it’s mostly @expede and @matheus23’s idea, but the high-level concept is to overlay a deterministic skip list onto the history, to be used in traversing the history in variable sized jumps.
There’s lots more to be said about this approach, but I don’t want to misrepresent the idea, since it was only briefly conveyed to me during my onboarding call with @expede. Feel free to edit with more information!
2. Consistent Contraction Hierarchy (Consistent Skip List?)
This idea combines two different concepts: hash partitioning (sometimes called consistent hashing), and contraction hierarchies.
Hash Partitioning
Hash partitioning is an algorithm that’s typically used for distributing a value among a number of possible buckets, in a distributed fashion, with minimal coordination.
In its simplest case, it works by partitioning the output of a hash function into n buckets, and then hashing a given value: the resulting hash will map to one of those n buckets. Since every client will compute the same bucket for the same values, this is sometimes used in distributed databases, as a technique for choosing which shard of a cluster the data should be stored on.
From “Designing Data-Intensive Applications”:

We’ll get back to this idea after discussing contraction hierarchies.
Contraction Hierarchies
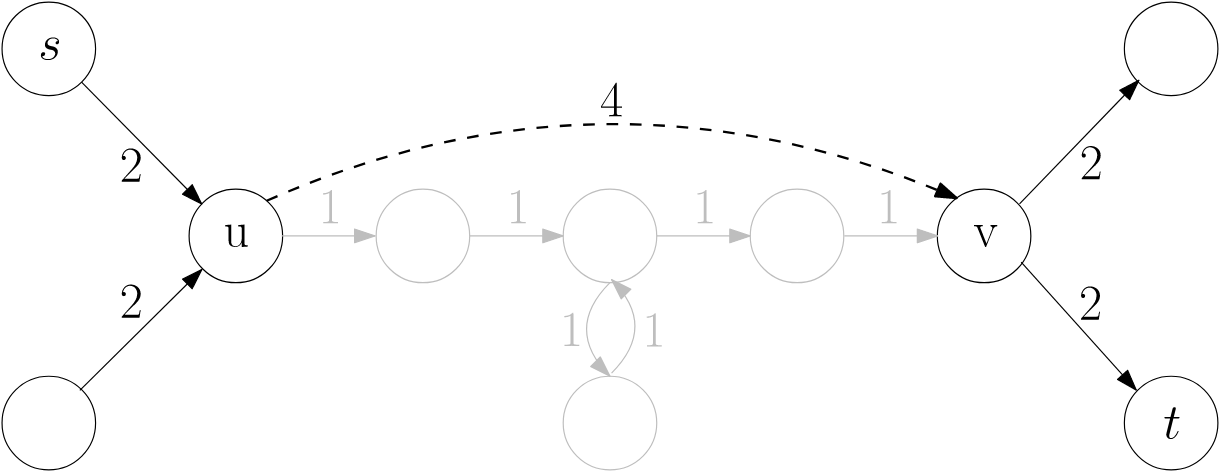
Contraction hierarchies can be used to speed up the process of finding the shortest path in a graph. The idea is to associate a graph with a simpler “contraction” of that graph, such that rather than searching the original graph, you can simply search the contraction and then map the discovered path back to the original graph in order to prune the search space.
In the below example, pre-computing the shortest path between u and v means that finding the shortest path from s and t can simply reuse that path as a “shortcut”.
This shows up in navigation systems. For example, if I want to find the shortest path from the University of Waterloo to the University of Toronto, and every intersection in the country is stored in a graph, it doesn’t make sense to search every possible path between both endpoints. Instead, a simpler “contraction” can be precomputed, that stores the shortest path between every city in the country.
Now, the problem has been reduced to finding the shortest path from the University of Waterloo to the perimeter of Waterloo, and from the perimeter of Toronto to the University of Toronto: everything in between can use the precomputed path linking the two cities. Further optimizations can be achieved by layering on multiple granularities of contractions on top of each other.
In the case of a graph that describes the roads in a country, its obvious how to contract the graph to achieve this sort of nesting: you use stable and meaningful geographic markers like “post offices”, “major intersections”, or “highway on-ramps”. But how do you achieve the same thing in the abstract world of content-addressable filesystems?
Combining the Two
To me, our fundamental problem is one of choosing consistent breakpoints in the history, in a distributed fashion, such that they can be used to select the nodes that belong to a given contraction. If we can achieve that, then we can construct contraction hierarchies over the revision history for a WNFS filesystem, that map to approximate indices into that history, and we can use those as checkpoints when searching for a least common ancestor.
While hash partitioning is typically used for partitioning space into a number of buckets, I think we can use the same idea to partition time in a similar way. The general approach I have in mind is to use the hashes of the CIDs within a revision history to bucket those revisions into different levels of the hierarchy, such that neighboring revisions within a given contraction represent predictable and consistent jumps through the history.
One way to do this is to steal Bitcoin’s idea of a hash target. Since CIDs are uniformly distributed, we can define a target “width”, w, for each level of the hierarchy, and choose a hash target for that level such that we’re expected to a find a CID below that target every w revisions. By arranging these targets end to end into non-overlapping intervals, we partition the CID-space into a contraction hierarchy that matches our desired properties!
The choice of hash target essentially maps to the birthday problem. In our case, the width of a contraction gives the number of people required for a 50% chance of hitting our target, and we’re solving for the number of “days”, D, such that hash_target = 2**32/D. Calculators for the birthday problem exist, and a particularly nice one can be found here.
Now, when adding new revisions to IPFS, in addition to back-pointers to the previous revision, they can also include pointers to the previous revisions under each level of the contraction hierarchy! Let’s call these “checkpoint” revisions.
Since the hierarchies are consistently constructed regardless of reference point, this means that finding the least common ancestor of two nodes reduces to walking backwards along the largest contraction in the hierarchy until a common checkpoint is found.
The process can then be repeated for each smaller contraction, beginning with the predecessor of the shared ancestor for the previous contraction, until the least common ancestor has been found. This allows us to move along the revision history in massive leaps, while guaranteeing that we eventually find the common ancestor.
Consider this example:
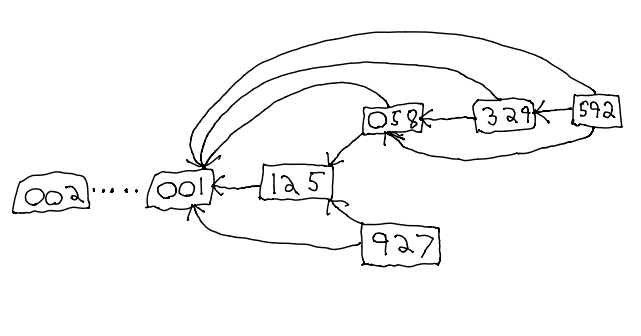
Here we have a contraction hierarchy made up of two contractions, plus the per-revision linked list we have now. Each contraction is computed based on the number of zeros at the beginning of the hash: the widest contraction is made up of the nodes with two leading zeroes, and next with nodes having one leading zero.
If we want to find the least common ancestor of nodes 592 and 927, we start by comparing the pointers for the widest contraction: since both point to 001, we know that the least common ancestor appears after 001. Now we follow the pointers for the next level of contraction, and end up at 125 and 058. Since both share ancestors under this level of transaction, we consider the linked list of revisions, and immediately see that 058 links to 125, which must be the least common ancestor for 592 and 927.
For this example, the hashes are made up, and the points don’t matter, but this whole search happens using 2 round-trips (fetching 125 and 058), versus 3 with only a linked list (329, 058, 125).
In a sense, because the hash function partitions the timeline into intervals, with some consistent checkpoint as their start-point, we’re always able to find our position relative to absolute checkpoints into that history, even if we’re not aware of our precise index through the timeline. This anchors the search to these checkpoints and prunes out everything else. I don’t think it would be inaccurate to say that the resulting structure mirrors that of a skip list, where relative links are replaced with absolute links.
Implementation Details
The above is a high-level sketch of the idea, but there still exist a few implementation details to be worked out:
- How large should the contraction hierarchy be?
- Less contractions ⇒ less time-efficient to search within the interval given by the widest contraction
- More contractions ⇒ less space-efficient to store the links within that interval
- What should the width of each contraction be?
- Wider contractions ⇒ more contractions required to efficiently navigate the interval give by that contraction
- Narrower contractions ⇒ fewer contractions required to efficiently navigate that interval
- How many back-pointers should each node store for each contraction?
- Rather than traversing backward one pointer at a time, we can store pointers to the last
knodes for each contraction - Reduces the round trips needed to find the common ancestor for each contraction
- Increases the storage costs of each node
- Rather than traversing backward one pointer at a time, we can store pointers to the last
- Should the pointers to the last node in the contraction be stored in IPFS, or constructed locally?
- Storing them remotely allows them to be reused by multiple clients
- Perhaps it’s uncommon for multiple clients to be working off the same divergent branch of history? If most clients work off their own branch, then this work may not be reused anyway
- Can instead track them locally, as revisions are added
- Possible middle-ground: checkpoint nodes store pointers to other checkpoints, but most revisions do not?
- Once a checkpoint has been found, you can quickly navigate the history, but avoid storing these pointers on other nodes, and instead cache them in memory
Conclusion
I have no idea how often this problem ends up being a bottleneck in practice, or whether it’s worth spending too much time exploring an optimization to what’s already there, but an approach like those described above may go a long way toward speeding up pathological cases to do with merging public WNFS trees.
I’m personally a fan of the contraction hierarchy approach: the way it partitions the timeline into roughly fixed-width intervals that we can reason about independently seems like a powerful abstraction for reducing this problem in cases where timelines have diverged over hundreds or thousands of revisions.
That being said, I recognize that I’m biased here, and also that I haven’t given the skip list approach as detailed of a treatment, so I invite anyone with a clearer idea of the skip list proposal to flesh that section out with more details if they think there’s more worth exploring there!
Anyway, my larger goal was just to document these thoughts!

 We should figure out the exact skip weights, and design the exact details of reconciliation search
We should figure out the exact skip weights, and design the exact details of reconciliation search